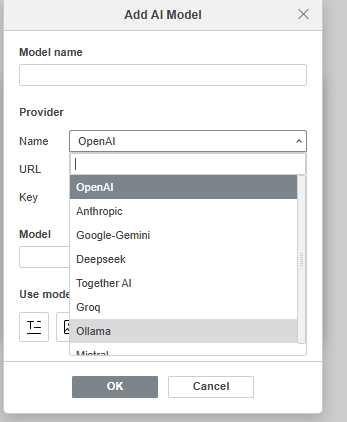
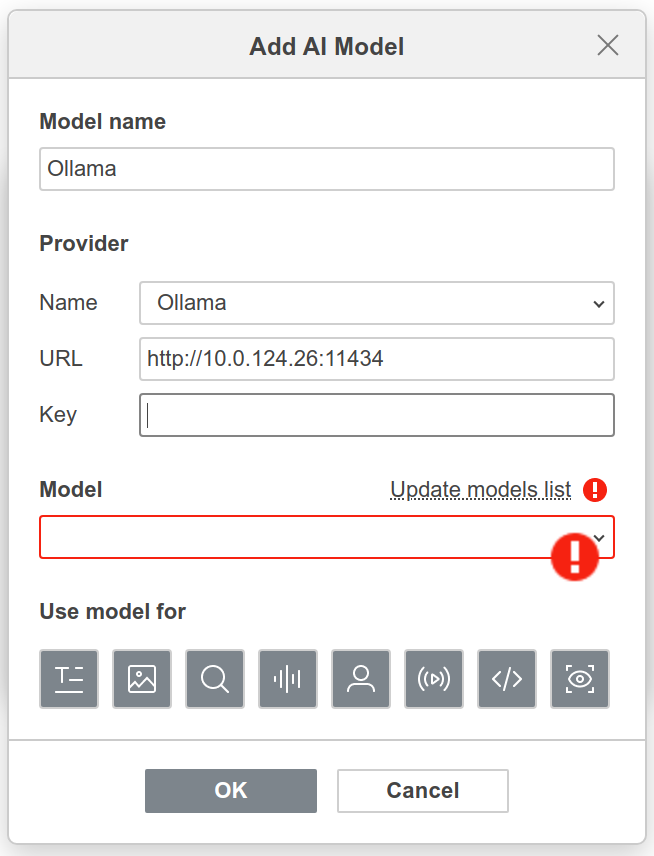
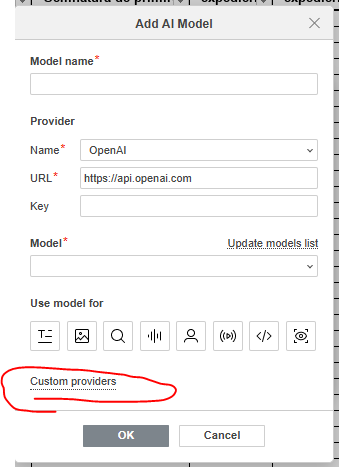
Sorry for the long reply, but there is a lot to go over. We are a small private lab that uses Ollama on an in-house server with a semi-custom Large Language Model (LLM) as a generative AI in several roles. We use our own in-house AI for the same reason we use ONLYOFFICE; privacy and security. As you surmised, a large amount of our interaction with the AI uses Open-WebUI, but not all.
Our stack is Debian, Docker, Ollama, Open-WebUI, and ONLYOFFICE, located on two machines connected with a high speed backbone. The AI server with GPUs runs on one machine with a research library running on a Debian server attached to a rather large RAID array. When we renew our equipment, we will be looking at putting the entire stack and GPUs on a single machine and cloning it for high availability and failover. This will simplify deployment, reduce power consumption, and increase reliability.
Our specific uses, which I believe will not be unique in the future, uses local AI in several roles:
-
Use a large language model to generate a comprehensive list of topics to write about, or to use as topics in a document outline.
-
Generate the text of a document, then edit the document in order to both validate the AI generated material and put it in the author’s “voice”.
-
Edit an existing document to raise or lower the vocabulary level to match the education of the anticipated reader.
-
Translate a document form any language to any language that the LLM is capable of.
-
Go through material from our library server (approx. 27TB of research data in various scientific disciplines) from text documents, pdfs, and LaTex to pictures and videos, looking for specific combinations of keywords, contexts, and tags, returning these as citations to go through for relevance including the properly formatted citation which may be directly pasted into the reference section of the paper. This more of a RAG than traditional LLM, but the interface is the same.
-
Go through scientific journals and other academic information clearing houses looking for the same as the above. This application is more of a “web scrape”. Again, the interface is the same.
-
Analyze large volumes of data from a database or spreadsheet to find specific patterns or correlations, doing so with a simple, clearly stated request, and outputting the results to a spreadsheet and/or document table as an example or appendix.
-
Work through a development or problem with an interaction with a researcher using all the capabilities listed above, then output the findings in a standardized document template. Once this document is reviewed by the researcher, it is stored on the researcher’s private folder(s) and/or the shared library server mentioned above.
-
Generate a glossary of terms, both those used in the document and terms used in the subject matter trade-space or domain. This helps build capability of the reader even when their experience and/or expertise in the subject matter is limited. We generally put this in as an appendix in jargon- and acronym-heavy documents, and our AI helps us identify these as well.
-
Check the document against a list of internal secrets, classified, or embargoed data to properly classify the document, limiting access to personnel cleared for it, and recommending edits to obscure sensitive data prior to release in the form of publication, peer review, or press releases.
The result for us is that this automates a large amount of the repetitive tasks associated with scientific research documentation, and we have other forms of automation capable of doing much of the other repetitive work as well, reducing human error and some bias. We are capable of research that labs ten times our size and larger would take decades to perform, performing it better and in weeks or months.
The integration with ONLYOFFICE we would love to see is pretty much what we are currently doing manually, but obviously make it less scientific research specific:
-
Direct connection to localhost or remote server Ollama based AI (port 11434) with a dialog box and the option to keep the data in the chat box to cut and paste it, or output it directly in the document you are working on.
-
Show the AI as a collaborator in the document when you go into the versioning so that you can easily see changes. This would also be helpful if the AI is annotating the document as well.
-
Full translation of a document, generating a new document as output with an extended file name indicating AI translation. In our case Erforschungsdokument.docx would produce Erforschungsdokument [AI_DE-EN].docx as the English translated document.
-
Similarly, documents may be reworded to change the tone, length, and/or reading level with a change in the filename to indicate the modification. As an example, converting a PhD level paper to an American 12th grade reading level at 400 words would take PhD_document.docx and produce PhD_document [AI_PhD-12_400w].docx. This is incredibly useful in press releases.
-
The ability to generate whole documents from output, either free form or following a template, placing them in a folder for human review, or flagging them in some other way (tag and/or watermark?).
-
Generate a list of material from a body of data using online as well as local resources which match the query. In our case we use such a list to identify supporting as well as contradictory material.
-
Generate a glossary of terms as a chapter or appendix as mentioned above.
-
Where external material is used, help the author properly cite the sources, both using the inline forms as well as the standard reference formats (APA, MLA, Chicago, and Turabian), pasting these in the appropriate place in the document.
-
Allow the AI to produce new tabs in a spreadsheet or generate entirely new spreadsheets to output requested data. Modifying existing sheets may also be done, but should only be allowed within specifically defined ranges to prevent inadvertent overwriting.
Much of this could be accomplished by creating a plugin that connects to the Ollama port on the server (127.0.0.1:11434 or 192.168.1.8:11434 as examples), then becomes a user on the OPENOFFICE system that the user can make requests from. The rest is largely template driven, which can be accomplished on the LLM side as we are doing now and/or within the ONLYOFFICE plugin.
Other applications of such a system include the automation of general clerical work, technical reports in various industries, and numerous others. While this addition to ONLYOFFICE would only eliminate a bit of cut and paste for us, it is a feature set that would completely set your office suite apart from the others once again.
integrators would be able to deploy turnkey solutions based on the stack of Ollama, Open-WebUI, and ONLYOFFICE. We were considering spinning off a company to do just that, even generating our own ONLYOFFICE plugin to do the things outlined here, but our board ultimately decided that this would be a distraction to what we already do. That said, we would be interested in helping others accomplish this.